Product
Creating Fairness in Azure Service Bus in a Multi-Tenant Setup

Emil Rasmussen
CTO at Enterspeed

Enterspeed is a multi-tenant SaaS platform. This model is one of the strengths behind our scalability strategy and important in realising our vision: We want to make high performing and scalable APIs easier and more affordable for everyone. However, in a multi-tenant environment, there's a risk of 'noisy neighbours'.
In this blog post, we'll give you a peek behind the scenes to show how we've created fairness in the processing of customer jobs. But before we delve into the solution, let's set the scene by explaining our existing setup.
Our setup is primarily based on managed and serverless services in Azure. Initially, we sought for a solution to the 'noisy neighbours' in Azure's guidelines, but it turned out that our specific problem didn't fit within these guidelines.
Simplified, our former processing model involved adding each customer job as a message to the Service Bus. A Service Bus triggered Azure Function, acting as the consumer service, then undertook the actual work of processing the job. The Azure Function workers ran on an Elastic Premium plan, ensuring we always had at least one warm and ready function to handle new messages, and capable of scaling up quickly when the number of jobs increased. This strategy served as a great compromise between performance and cost.
However, the issue with this model is that the Service Bus operates as a FIFO queue. For us, this means that a single customer could potentially insert hundreds of thousands of jobs, causing subsequent customers to wait for these jobs to finish processing before their singular job could be processed. Naturally, nobody wants noisy neighbours crowding the hallways and causing delays.

Hence, we had to devise a solution.
As mentioned earlier, our specific problem and setup didn't find a fitting solution within the Microsoft Azure landscape. The typical guidelines for multi-tenancy suggest creating tenant-specific "topic or queue resources". However, both the cost and operational complexity of this approach exceeded what we were willing to accept.
Our goal was to distribute processing capacity fairly among customers. The algorithm chosen for distributing the capacity fairly has the fancy name interleaved weighted round robin and is heavily inspired by the concept of a sharded queue.
Conceptually, this idea is simple: We’ll feed all potential jobs into a temporary queue, then, at regular intervals, take an equal number of jobs from each customer and insert them into the actual processing queue.
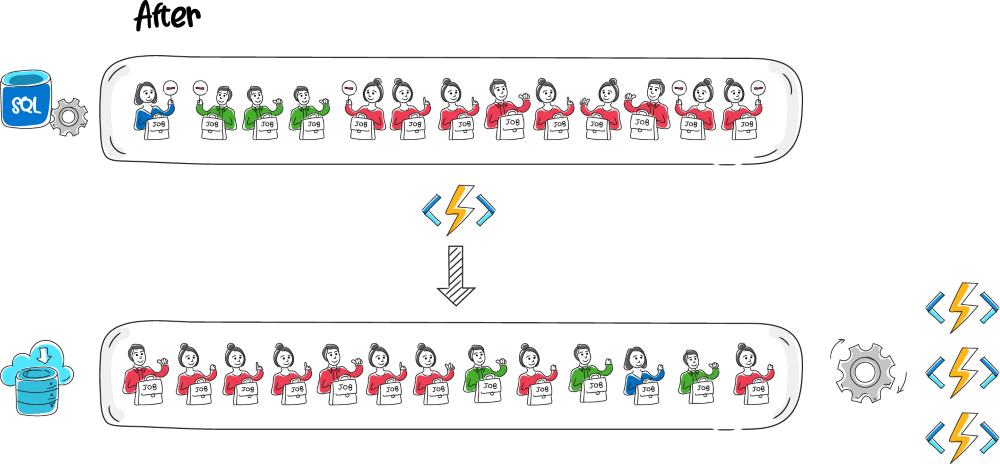
The implementation was also simple, although we learned a couple of things the hard way, but let’s get back to that later.
We added two new concepts to our processing layer:
One of the main benefits is that we can continue using our existing processing queue and processing functions without any big changes. Another benefit is that the distributor enables a much better control of the flow into the processing layer.
As mentioned, we did have to learn a couple of things the hard way.
By the way, did you know that you can Sign up for Enterspeed directly through Microsoft Azure Marketplace?
The first big lesson was the choice of datastore to use for the temporary queue. After trying both Azure Service Bus and Cosmos DB, we settled on a good old-fashioned SQL Server – specifically, Azure SQL Database on the serverless pricing tier.
We did complete implementations for both Service Bus and Cosmos DB. In regard to Service Bus, we learned that the throughput was unpredictable, and the querying capabilities were limited. Cosmos DB is predictable and has great querying capabilities but is also expensive to scale as we have a very spiky throughput pattern.
We chose the SQL server because it enables us to query the temporary jobs table efficiently and effectively, boasting predictable performance/cost characteristics.
The querying capabilities of traditional RDBMS like SQL Server also make it easy to implement a feature that allows us to create larger batch sizes for our most sizable customers, thereby prioritising them.
We are always wary of using "new" technology, and we tried out Service Bus and Cosmos DB first because they were already well known to us. When we implemented the distributor Azure function, we learned that "tried and tested" isn't always the best option.
All of our Azure functions had previously been upgraded to .NET 6, but we stayed on the in-process runtime. So, of course, we also stayed with the in-process runtime for our distributor function. But we encountered an unexpected problem while running the function as a timer triggered. It would take a "coffee break" and simply just stop – sometimes continuing some minutes later and sometimes just stopping indefinitely. Note that it didn't crash or otherwise show any signs of not functioning – just... nothing.
It took some trial and error, but we found a solution. So, if anyone reading this ever finds themselves in the same situation, we can tell you that the solution is to run the timer-triggered Azure Function as an isolated worker process. We never found out why we experienced problems, but isolated workers is a change that is coming with .NET 7, so we would eventually go down that route anyway. Another hard-earned lesson, but all in all a relatively easy fix.
As a sidenote, we want to mention the instrumentation. We strongly advocate for what you could call "instrumentation first". Throughout the experiments with various data stores and the issue with the timer-triggered Azure function, we relied heavily on a custom set of Elastic dashboards to monitor the performance of the various components. When working with a distributed microservice architecture, detailed insights into your application are essential.
We're extremely pleased with how our fair processing queue operates, and it has given us more control over the flow of jobs. However, one downside is that the timer-triggered functions have slightly increased our processing latency. With the Service Bus triggered functions, we experienced almost immediate latency, but the timer-triggered model necessitates waiting until the next interval. It's a compromise we're currently willing to accept. Previously, one customer could create hours of latency for others in extreme scenarios. Now, with the fair processing model, the latency is slightly higher on average but far more consistent. Eventually, we aim to reduce this latency.
With the objective of fairness between customers achieved, we are looking into differentiating on environments. A somewhat typical use case is to test out the entire development environment, and in some cases, that can create a backlog while the processing layer prepares the data for the Delivery API. In such cases, also the customer’s production environment will have to wait for the development environment to finish processing.
Want to know more about how we process data in Enterspeed? Check out our key features Ingest API, Schema designer, and Delivery API.
20 years of experience with web technology and software engineering. Loves candy, cake, and coaching soccer.
© 2020 - 2026 Enterspeed A/S. All rights reserved.
Made with ❤️ and ☕ in Denmark.