Thoughts & Insights
All you (probably) need to know about caching on the web

Kasper Andreassen
UX Engineer at Enterspeed

Every developer has most likely bumped into the concept of caching at some point in their career.
For some, it’s a vital instrument in their everyday work that helps their code to run as fast and cost-effective as possible.
For others, they might only have worked with it that one time they activated “that cache plugin” on a client’s WordPress site.
If you belong to the first group, you probably won’t need this article. Instead, you can enjoy a nice game of “Chrome dino”. Open a Chrome browser and type: chrome://dino/
For all you people not so well-travelled in the world of cache, I know you’re dying to also play a nice game of “Chrome dino”, but patience you must have my young Padawan – your time will also come.

First, let’s look at what cache is and how it works.
Caching is the process of temporarily storing copies of data, so it can be accessed more quickly.
It’s a concept that has been used in computer science for ages, going all the way back to 1965 when British computer scientist Maurice Wilkes introduced memory caching.
But copying things doesn’t necessarily make them faster, Let’s look at three examples.
In the first example, we’ll see how you can reduce the server’s workload by turning your dynamic content into static content.
Back in the early days of the web, all websites that existed were static – it was all pure, simple HTML.
Then in the mid 90’s that all changed when multiple server-side languages were released (PHP, ASP, etc.), as well as one client-side scripting language called JavaScript
Dynamic pages revolutionised the web and made websites more personalised and interactive. However, it also made the web a bit slower since the user now had to wait for a server to render the content.
Having the server create the content every single time a user visited, even though nothing had changed, seemed a tad bit silly, so developers started implementing caching.
The caching worked by saving a copy of the “server response”, turning the dynamic content into static content.
That way they could generate content upfront and serve it both quicker and cheaper to the user – they just had to remember to invalidate it when the content changed.
Let’s see what this could look like in the real world.

Imagine a restaurant serving “soup of the day”. Each day a new, different soup is available.
Which soup is available that day, may depend on which ingredients are in surplus in the kitchen and what the chef feels like making.
Since the restaurant doesn’t know what the soup of the day will be, they can only write “Soup of the day – ask the waiter” on their menu.
(It’s really difficult for me not to write a witty ‘ask the server’-pun here).
That’s fine for a small restaurant, or one where a waiter takes your order each time. Now imagine a busy street food restaurant serving hundreds of customers throughout the day.
Getting asked, “What is today's soup?” a hundred times a day, every single day, would turn any man or woman into a Soup Nazi, yelling “NO SOUP FOR YOU!” the 249th time this question was asked.

The restaurant could instead “cache” this request by writing “Soup of the day: Chicken soup” on a blackboard above the counter.
The chef could then easily “invalidate” this cache once a day, when the soup changed, or when the soup is sold out.
In the next example, we will see how we can get the soup… Sorry, I mean content, closer to the user by using caching.
The location of a server hosting a website can greatly impact the website’s speed.
If the user is located far away from the server, their response will be slow compared to someone located close to the server.
The closer the user is to the server, the quicker the response. This is also why there’s big money in renting out servers as close to the stock exchanges as possible – for high-speed trading bots, every millisecond counts.
Luckily, we don’t need to have the servers quite as close to the users, as a trading bot needs to be to a “trading floor”, but we need it to be somewhat close to their geographic area.
Setting up multiple independent servers to serve multiple geographic areas can be both inefficient, costly, hard to scale, and a nightmare to manage. Luckily there’s a better solution – a CDN.
A CDN, Content Delivery Network, is a group of servers distributed geographically that work together to deliver your content fast to the user.
It stores a copy of your data, including HTML pages, JavaScript files, stylesheets, images, and even videos.
CDN providers have a ton of locations available. Cloudflare, for instance, has 275 servers in more than 100 countries – imagine if you had to set that up yourself!
Let’s try to translate a CDN into a real-world example.
Say you are an electrical contractor and run a successful company with several employees under you. Since you’re an electrical contractor and not a baker, you need to go to your customers instead of your customers coming to you.
The customers can be located far away from the workshop, where you store all your tools, cables, and other supplies.
Having to go back and forth from the workshop to the customer, each time you need a tool or cable would be quite cumbersome.
Instead, the electrician “caches” his most used tools and supplies in his van. That way the things he needs are close to him, and he can quickly grab what he needs.
Each day when he gets back to the workshop, he can “revalidate his cache” by filling up the vans with new supplies, charging his electrical tools, and preparing the van for the next job.

Image source: https://www.fieldpulse.com/blog/electrician-van-setup/
In the last example, we will see how we can cache our data to faster storage solutions.
All storage is not “built the same”. You'll know what I'm talking about if you have ever switched from using a hard drive to an SSD.
Hard drives, which store the data on mechanical spinning disks are great at storing a large amount of data since they are incredibly cheap when it comes to “cost per GB”.
However, having mechanical parts just isn’t as fast as something without any moving parts, like an SSD, which stores its data on flash memory. SSDs are much faster, but (as you may already have guessed) also more expensive.
Over the years many web hosts have started offering plans with SSD hosting to make their services even faster.
But do you know what’s even faster and way more expensive than SSD storage? RAM storage.
That’s right, you can store your files in the RAM. Benchmark has shown read speeds that were 6.3 times faster than the speed of an SSD – insane!
But no sane person would store websites in memory (RAM), would they? Indeed, they would.
Redis is an in-memory data store that you can use as a database – or a cache in front of your regular database. The speed of Redis makes it ideal to cache database queries, complex computations, API calls, and session state.
Now, I know what you are thinking. “I’m just a simple developer trying to make my way in the universe. I’m not going to set up and maintain a separate database merely for caching.”
I get that, boy do I get that. As the late Phil Karlton once stated: “There are only two hard things in Computer Science: cache invalidation and naming things”.
If only there was a way to reap the fruits of in-memory storage, without the hassle of setup, maintenance – and more importantly cache invalidation.
You can see where this is going, can’t you?

Yes, this is indeed shameless self-promotion. Don’t worry, I’ll be sure to whip myself 3 times afterward and put on the cone of shame for the rest of the day.
Enterspeed is a way to cache your data in a high-speed, in-memory storage, without the hassle of maintenance and cache invalidation.
We offload your data, which you can combine with multiple data sources (as well as transform), in a Redis database. What this does is essentially decouple your server, as well as make your dynamic content static.
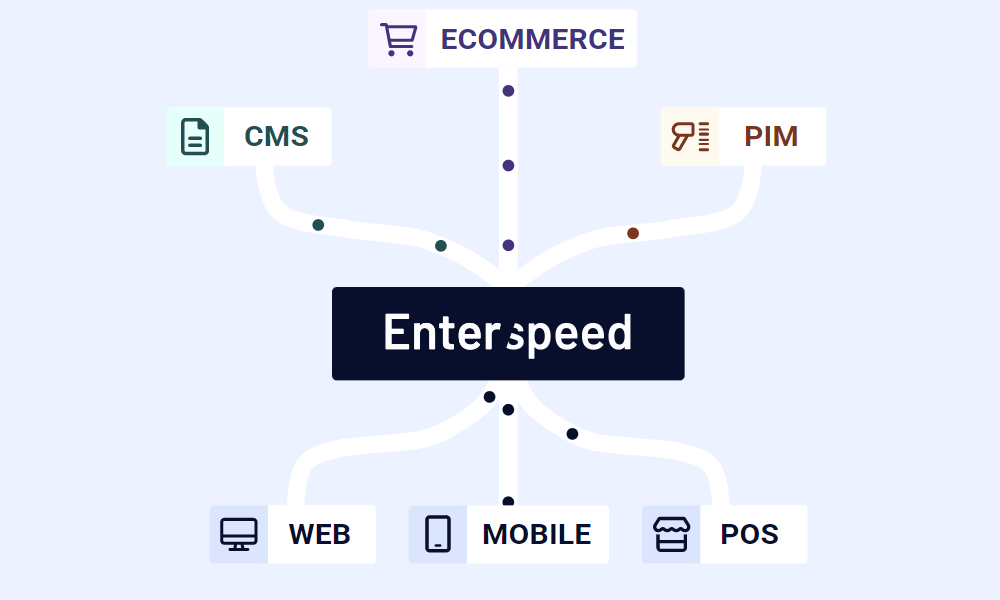
If you want to know more about how this all works, head over to Enterspeed.com to read more.
Well, that’s enough self-promotion (for now). Let’s look at the real-world example for this.
After thinking about it for many years, you’ve finally decided that you’re going to see Europe. You’ll take some months of work, rent an RV, and visit all the places you’ve dreamt about seeing.
An RV is perfect since you don’t have to plan far ahead and can stay at each place for as long as you like. One problem though. While an RV is great for many things, it isn’t exactly an easy or fast vehicle to operate – especially not on those tiny European streets.
You’ll need something else for those small sightseeing tours. Therefore, you decide to add a car to your travel plans.
What solves this problem, is an RV with built-in car storage. That way you can use your RV to travel from location to location, and the car to go sightseeing within the location.

Image source: https://www.concorde.eu/modelle/liner
If you’re not Scrooge McDuck, this could also simply be a bike, or a scooter placed on the back of the bus – but how cool is a freaking built-in car garage!
Now, before moving on to the “how to” of the article, let’s look at some of the different types of web caching.
There are several types of caching. Some of the most used in web caching includes:
Now you’re properly thinking: “Wait, isn’t client-side caching and browser caching the same thing?”.
Not exactly. They’re similar in the way they store their data (on the client), but they’re not the same thing. To add to the confusion, the way client-side caching can be implemented is by using the browser’s storage APIs.
However, what differentiates them isn’t how they store data but rather what types of data they store.
Client-side caching is used to store responses from the server, e.g., API requests, which then reduces the number of requests that need to be made to the server.
Browse caching on the other hand stores static resources like images, videos, fonts, stylesheets, HTML files, JavaScript files, etc.
Both client-side caching and browser caching are controlled by the user’s browser. The developer can control the cache headers (for instance when the cache should be invalidated), but it is ultimately up to the web browser to interpret and enforce them.
This brings us to Server-side caching which stores the cache on… you guessed it – the server. Here the developer is in full control. There are several types of server-side caching, some of those are:
The next type of caching is CDN caching, which we explained in the “Moving the content closer to the user”-example, so we won’t dive too much into that.
Finally, we have reverse proxy caching. A reverse proxy cache, also known as a reverse HTTP cache, is also a type of server-side cache.
It sits in front of the server(s) and acts as a buffer between the client and the server. When a request arrives, it’s forwarded to the server by the reverse proxy which then caches the response. Thus, future requests can be served from the cache instead of hitting the server.
A reverse proxy cache is therefore a great way to improve not only the performance of a website but also its scalability – a reverse proxy cache is also able to work as a load balancer.
Before moving on to some of the ways you can implement cache on your website, we need to look at two more types of cache – private and public cache.
Private caching is a cache that can only be accessed by a specific user or user group. It can be stored both client-side and server-side.
Some examples of things that can be stored in a private cache are:
Public caching, on the other hand, is accessible to all users and is often stored on the server. Some examples of things that are stored in a public cache are:
Now that’s all set, it’s time to move on to how you can use cache on your website using some “easy wins”.
Designing and setting up a caching strategy can be difficult. There are several ways to tackle cache and it all depends on how your setup looks and what your needs are.
If you’re using a CMS like WordPress, one of the quickest ways to start utilising cache is by installing a cache plugin.
One of the most beloved WordPress caching plugins is WP Rocket. They’ve managed to take something complex and make it extremely easy, yet still powerful and configurable. They have also made it easy to integrate with a CDN in just a few clicks.
Implementing a CDN is an extremely easy way to implement caching on your website.
If your site is built on the Jamstack principles, you are probably already using it via a provider like Netlify, Vercel, Cloudflare Pages, etc.
If not, then it’s as simple as setting up an account at a CDN provider and updating your nameservers. Cloudflare offers a generous free plan and is really simple to set up. You can read more about the setup here.
It’s no secret that I’m a big fan of Next.js and its many fantastic features. One of the features I adore is their Incremental Static Regeneration.
When rendering a page, the choice is usually between SSR (Server-side Rendering) or SSG (Static Site Generation). Due to the risk of poor SEO and slow initial load, CSR (Client-side Rendering) isn’t often used on “regular websites” (non-app websites).
SSR is great since it makes your pages dynamic but can be slow since it must wait for the server each time.
SSG is great since it’s super-fast but isn’t easy to update since you will have to do a deployment each time you want to change something.
Well, ISR completely changed the game. Like a peanut butter and jelly sandwich, it took two great things and combined them, making something even better. It combined the power of SSR with the power of SSG.
ISR caches each page individually. When a user visits the page, it will check if there is new content available. If there is, it will start regenerating the page and once it’s done, invalidate the cache and show the updated page for the next visitor.
You can read more about Next.js ISR here.
If you are fetching data client-side, e.g., showing your visitors data from the Star Wars API, you should cache these responses.
If the user has already made a request to see all the starships in Star Wars, there’s no reason to make an identical request if the user wants to see it again. Instead, the response should be cached.
You can implement this yourself, for instance by using a state management solution, or something as simple as the State hook in React.
You can also use data fetching packages with built-in caching management, for instance, TanStack Query, SWR, etc.
I hope you enjoyed this article about caching. You are now free to play all the “Chrome Dino” that you wish.
The “Chrome Dino” game is shown in Chrome when you are offline. If you want to make your website/app work offline (making it a PWA), one of the ways you can store data is by using cache. You can read more about “offline data” here.
Loves optimizing and UX. Proud father of two boys and a girl. Scared of exercise and fond of beer.
© 2020 - 2026 Enterspeed A/S. All rights reserved.
Made with ❤️ and ☕ in Denmark.