Product
Introducing the Enterspeed Query API

Jesper Weber
Senior Software Engineer at Enterspeed

Dynamic lists, native filtering, and faster builds – right inside Enterspeed
This is for anyone who’s worked with larger lists in Enterspeed. Because we see you 😉
Until now, getting pagination, filtering, and sorting to play nicely often meant duct-taping external tools or reprocessing static lists. Not ideal for fast-moving frontends or complex datasets.
That changes now.
Say hello to the Enterspeed Query API – a new, integrated way to query and shape your data dynamically, with built-in support for filtering, pagination, sorting, and facets.
🎥 Watch Senior Software Engineer Jesper Weber walk through the new Query API in action in this video
Lists are everywhere – from product catalogues and blog feeds to search results and tagged content collections. But in Enterspeed, lists used to be static: once processed, they couldn’t easily be filtered or paginated without reprocessing.
The Query API fixes that. You can now:
🔎 Query indexed data directly
⚙️ Filter, sort, and paginate dynamically
🧮 Retrieve facet data for grouped views
🧩 Reference dynamic views directly at query time
All of it runs natively inside Enterspeed – no external indexing required for typical use cases.
At the heart of it is a new schema type: the Index Schema.
If you’ve built with Enterspeed before, it’ll feel familiar. You still define fields and mappings – but now, you can specify what gets indexed and how it behaves.
Example:
You can create a blogIndex schema with fields like publishDate, title, authorName, and tags – even specify types such as keyword[] for tags.
Then, just like any other schema, you:
Your data is now indexed and ready for dynamic querying.
📘 Learn more about schemas in the Enterspeed documentation: Index schemas | Enterspeed Docs ↗
Example of a simple index schema in javascript:
1/** @type {Enterspeed.IndexSchema} */
2 export default {
3 triggers: function(context) {
4 context.triggers('blog', ['blogPost'])
5 },
6 index: {
7 fields: {
8 publishedDate: { type: "date" },
9 title: { type: "text" },
10 authorName: { type: "text" },
11 tags: { type: "keyword[]" }
12 }
13 },
14 properties: function (sourceEntity) {
15 return {
16 publishedDate: sourceEntity.properties.published_date,
17 title: sourceEntity.properties.title,
18 authorName: sourceEntity.properties.author.name,
19 tags: sourceEntity.properties.tags
20 }
21 }
22} Here’s a small-but-mighty detail: version handling.
When you deploy a new index schema version, your frontend keeps running on the old one until the new version is fully ready.
Once it’s live, Enterspeed automatically swaps versions – meaning no data mismatches during deploys.
Manual swaps are on the way, too, so you’ll soon be able to trigger version changes directly from the Management App or the CLI in your CI/CD pipeline.
You’ll find a new Indexes page in the Management App – it’s your playground for exploring, testing, and debugging queries.
Here, you can:
Inspect indexed items
Edit and test raw queries
Add filters (like authorName = Jane Doe)
Adjust pagination and sorting
It’s a great way to experiment before integrating your queries in Postman or your frontend.
You can explore the Enterspeed Management App right here ↗.
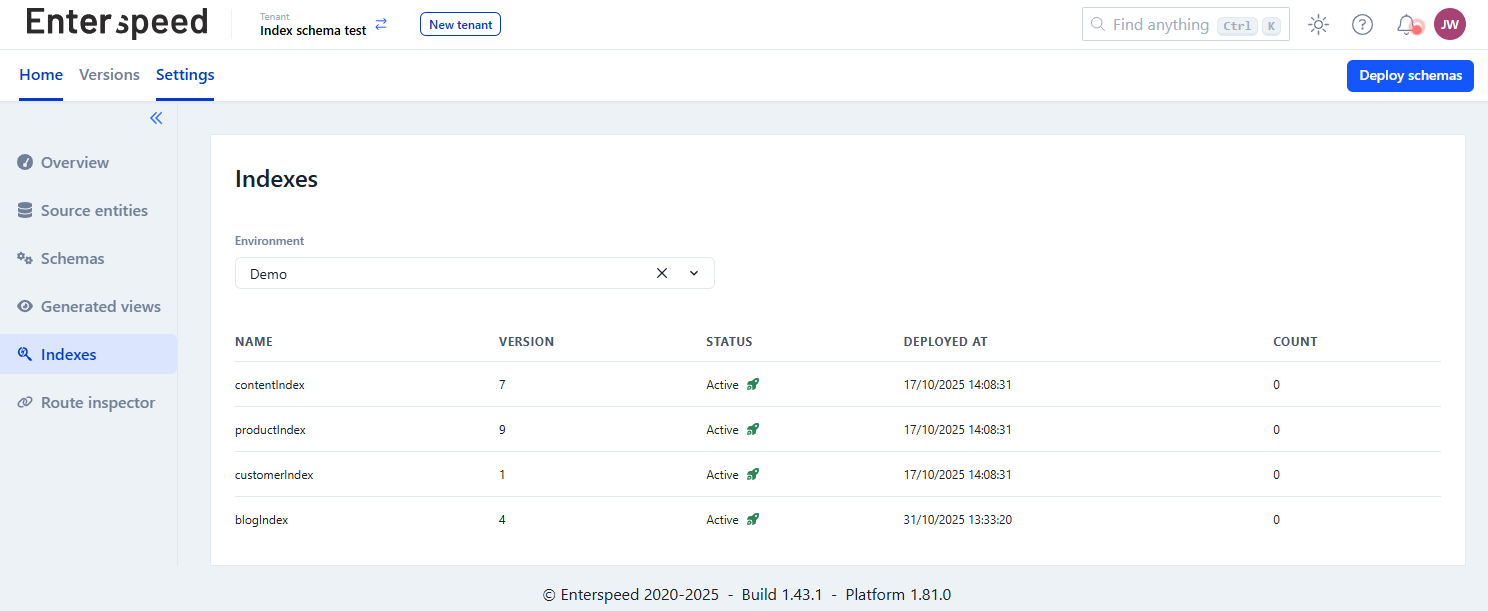
The indexes page in the Enterspeed Management App
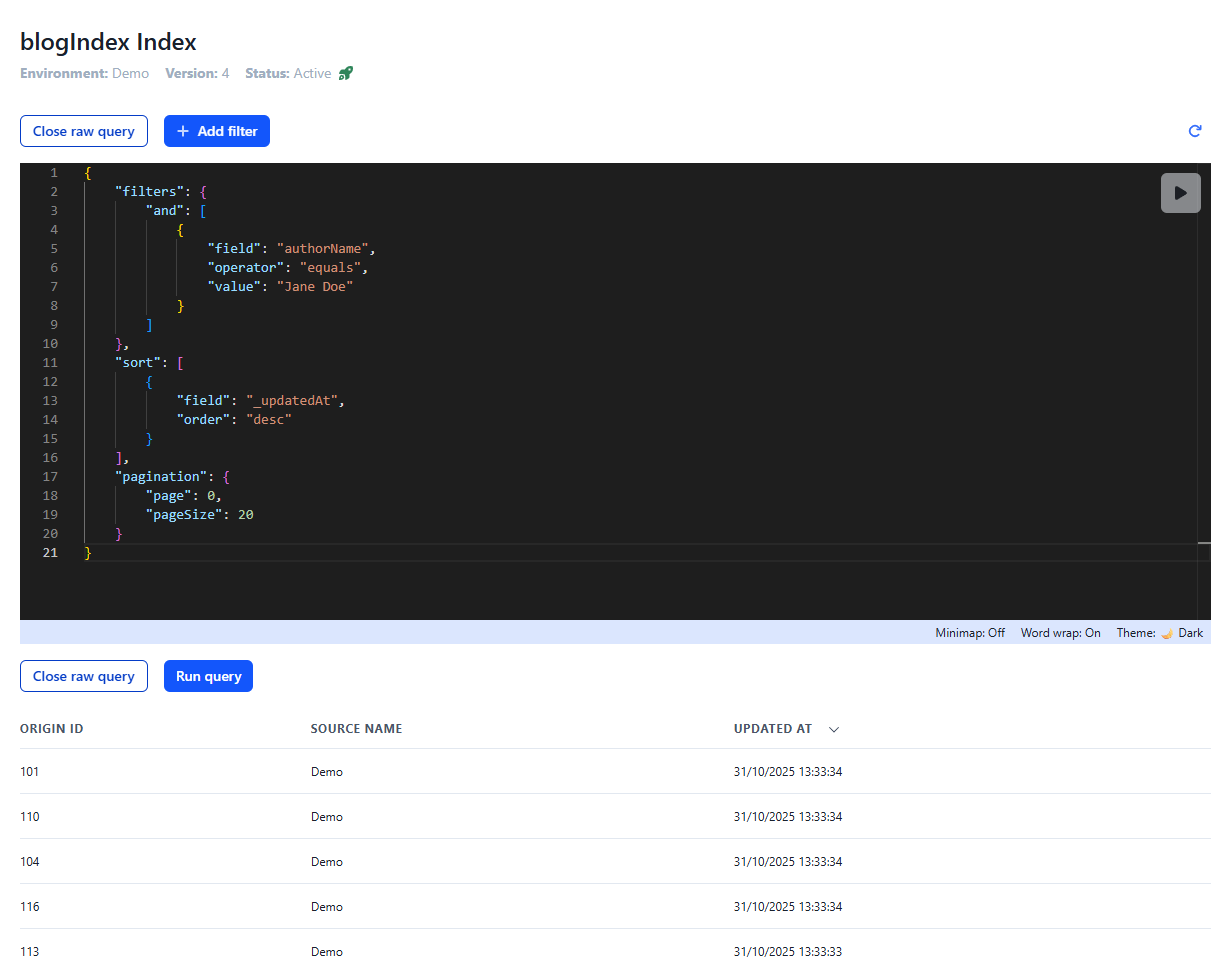
The Query editor with filters and pagination controls
Need to group and count items dynamically (e.g. by tags or categories)? Facets make that easy.
You can name facet groups, limit how many results to return, and even run multiple facets in one go.
To get a sense of the data structure, check out this short JSON snippet of a Query API request and response showing a facet group.
1{
2 "facets": [{ "field": "tags", "name": "Tags", "size": 3 }]
3} And the response:
1{
2 "facets": [
3 {
4 "name": "Tags",
5 "field": "tags",
6 "groups": [
7 {
8 "value": "AI",
9 "count": 20
10 },
11 {
12 "value": "LLM",
13 "count": 4
14 },
15 {
16 "value": "Edge",
17 "count": 2
18 }
19 ],
20 "isValid": true
21 }
22 ]
23} Query one index and pull in multiple view schemas.
For example:
BlogPostTile for list views
BlogPostDetails for full post pages
You can include both in one request – which means fewer API calls and more consistent data delivery.
Need both a filtered query and an unfiltered facet overview?
Bundle them into a single request – the Query API handles it gracefully.
📘 Check out the full Query API documentation
When (and when not) to use itIf you need advanced full-text search – synonyms, typo handling, or natural language understanding – tools like Algolia, Typesense, or Relewise still shine. But for structured, dynamic lists – think blogs, product grids, category pages, or archives – the Enterspeed Query API is your new best friend. |
The Enterspeed Query API takes dynamic data from “possible with workarounds” to fully integrated and fast.
Filtering, pagination, sorting, and facets are now first-class citizens inside Enterspeed.
Big thanks to Jesper Weber for the walkthrough – and to all the developers already building smarter, faster frontends with Enterspeed.
👉 Watch the full video walkthrough on YouTube
👉 Dive into the Query API documentation: API documentation | Enterspeed Docs


It has just become 100 times easier to fetch data from Enterspeed. We've opened a public preview of the Enterspeed Query API. With the Query API, you can create dynamic queries on the data you have in Enterspeed.
Loves building software that makes an impact on businesses. Untalented but happy ice hockey player (the beers just taste better in a locker room after a game...)
© 2020 - 2026 Enterspeed A/S. All rights reserved.
Made with ❤️ and ☕ in Denmark.

